
Dans la course au développement d’une intelligence artificielle avancée, tous les grands modèles de langage ne sont pas égaux. Deux nouvelles études révèlent des différences frappantes dans les capacités de systèmes populaires comme ChatGPT lorsqu’ils sont mis à l’épreuve sur des tâches complexes dans le monde réel.
Selon des chercheurs de l’université de Purdue, ChatGPT a du mal à relever les défis de codage les plus élémentaires. L’équipe a évalué les réponses de ChatGPT à plus de 500 questions sur Stack Overflow, une communauté en ligne pour les développeurs et les programmeurs, sur des sujets tels que le débogage et l’utilisation de l’API.
« Notre analyse montre que 52 % des réponses générées par ChatGPT sont incorrectes et 77 % sont verbeuses », écrivent les chercheurs. « Cependant, les réponses du ChatGPT sont encore préférées dans 39,34 % des cas en raison de leur exhaustivité et de leur style de langage bien articulé. «
En revanche, une étude de l’UCLA et de l’université Pepperdine de Malibu démontre les prouesses de ChatGPT pour répondre à des questions d’examen médical difficiles. Interrogé sur plus de 850 questions à choix multiples en néphrologie, une spécialité avancée de la médecine interne, ChatGPT a obtenu un score de 73 %, similaire au taux de réussite des résidents en médecine humaine.
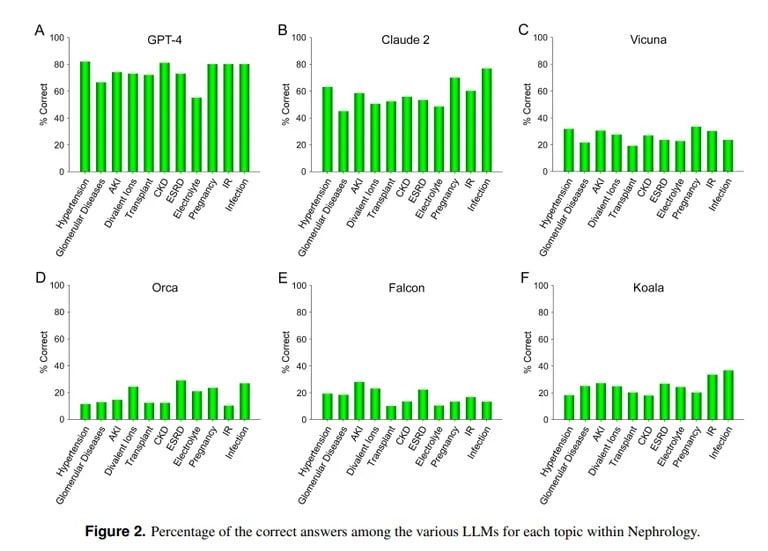
Image credit : UCLA via Arvix
« La capacité supérieure actuelle de GPT-4 à répondre avec précision à des questions à choix multiples en néphrologie laisse présager l’utilité de modèles d’IA similaires et plus performants dans de futures applications médicales », a conclu l’équipe de l’UCLA.
Claude AI d’Anthropic a été le deuxième meilleur LLM avec 54,4 % de réponses correctes. L’équipe a évalué d’autres LLM open-source, mais ils étaient loin d’être acceptables, le meilleur score étant de 25,5 % pour Vicuna.
Pourquoi ChatGPT excelle-t-il en médecine et échoue-t-il en codage ? Les modèles d’apprentissage automatique ont des forces différentes, explique Lex Fridman, informaticien au MIT. Claude, le modèle à l’origine des connaissances médicales de ChatGPT, a reçu des données d’entraînement propriétaires supplémentaires de la part de son fabricant Anthropic. Le modèle ChatGPT d’OpenAI ne s’est appuyé que sur des données accessibles au public. Les modèles d’IA font de grandes choses s’ils sont correctement entraînés avec d’énormes quantités de données, même mieux que la plupart des autres modèles.
Image courtesy : MIT
Toutefois, une IA ne sera pas en mesure d’agir correctement en dehors des paramètres sur lesquels elle a été entraînée. Elle essaiera donc de créer du contenu sans en avoir une connaissance préalable, ce qui donne lieu à ce que l’on appelle des hallucinations. Si l’ensemble de données d’un modèle d’IA ne comprend pas un contenu spécifique, il ne pourra pas produire de bons résultats dans ce domaine.
Comme l’expliquent les chercheurs de l’UCLA, « sans nier l’importance de la puissance de calcul de certains LLM, le manque d’accès gratuit aux données d’entraînement qui ne sont pas actuellement dans le domaine public restera probablement l’un des obstacles à l’amélioration des performances dans un avenir prévisible ».
L’incapacité du ChatGPT à coder s’aligne sur d’autres évaluations. Comme TCN l’a précédemment rapporté, des chercheurs de Stanford et de l’Université de Berkeley ont constaté que les compétences en mathématiques et en raisonnement visuel du ChatGPT ont fortement diminué entre mars et juin 2022. Bien qu’initialement doué pour les nombres premiers et les puzzles, il n’a obtenu que 2 % des points de référence clés à l’été.
Ainsi, si ChatGPT peut jouer au docteur, il lui reste encore beaucoup à apprendre avant de devenir un as de la programmation. Mais ce n’est pas loin de la réalité : après tout, combien de médecins connaissez-vous qui sont également des hackers compétents ?