
Se le voci del settore sono corrette, il sequel del gigante della tecnologia open source potrebbe essere lanciato all’inizio del 2024.
Meta non ha confermato ufficialmente queste voci, ma Mark Zuckerberg ha recentemente fatto luce sul futuro degli LLM (Large Language Models) di Meta ammettendo che Llama 3 è in fase di sviluppo. Tuttavia, ha chiarito che il nuovo modello di intelligenza artificiale sottostante è ancora in sospeso e che la priorità è quella di perfezionare Llama 2 per renderlo più facile da usare.
“Voglio dire che stiamo ancora modellando il prossimo modello”, ha detto in un’intervista podcast a proposito dell’intersezione tra IA e metaverso. “Abbiamo addestrato e rilasciato Llama 2 come modello open source, e ora c’è la necessità di integrarlo in qualche tipo di prodotto di consumo ………”.
“Ma sì, stiamo anche lavorando ai futuri modelli della fondazione e non ho notizie in merito”, ha continuato. Non so esattamente quando sarà pronta”.
Sebbene Meta non abbia confermato ufficialmente le indiscrezioni, i suoi cicli di sviluppo e i forti investimenti in hardware suggeriscono che l’azienda è vicina al rilascio di un nuovo prodotto. llama 1 e llama 2 sono stati rilasciati a sei mesi di distanza l’uno dall’altro e, se questo ritmo viene mantenuto, il nuovo llama 3 (che dovrebbe essere a livello OpenAI GPT-4) potrebbe essere rilasciato nella prima metà del 2024.
L’utente di Reddit llamaShill ha fornito un’analisi dettagliata dei cicli di sviluppo storici del meta-modello, alimentando ulteriormente le speculazioni.
L’utente suggerisce che l’addestramento di Llama 1 è durato da luglio 2022 a gennaio 2023, con Llama 2 immediatamente successivo fino a luglio 2023, il che rende probabile che l’addestramento di Llama 3 avvenga da luglio 2023 a gennaio 2024. Questi risultati sono in linea con la storia dell’intelligenza artificiale superiore di Meta, e l’azienda non vede l’ora di mostrare il suo prossimo progresso, in grado di rivaleggiare con le capacità del GPT-4.
Nel frattempo, i forum tecnologici e i social media di
sono stati invasi da discussioni su come la nuova versione potrebbe ripristinare il vantaggio competitivo di Meta. La comunità tecnologica ha anche messo insieme una possibile timeline a partire da frammenti di informazioni.
Valutato alla GenAI Social Conference di Meta:
“Abbiamo fatto i calcoli per la formazione dei Lama 3 e 4. Il piano prevede che Llama-3 sia buono come GPT-4”.
“Wow, se Llama-3 è buono come GPT-4, continuerete a renderlo disponibile come open source?”.
“Sì, lo faremo. Mi dispiace, aligneur”.
– jason (@agikoala) 25 agosto 2023
Più un piccolo dettaglio su Twitter: una conversazione presumibilmente ascoltata a un incontro sociale “Meta GenAI” e successivamente pubblicata su Twitter da Jason Way, un ricercatore di OpenAI. Secondo Jason Way, “abbiamo già la base computazionale necessaria per addestrare Lamas 3 e 4” e una fonte non specificata ha confermato che sarà disponibile come open source.
Nel frattempo, l’azienda ha stretto una partnership con Dell per rendere Llama 2 disponibile agli utenti aziendali, sottolineando il suo impegno per la privacy e la sicurezza, che è sia strategico che concomitante. Questo impegno è fondamentale perché Meta si prepara a sfidare giganti come OpenAI e Google.
Con Meta che integra l’intelligenza artificiale in molti dei suoi prodotti, è logico che l’azienda raddoppi gli sforzi per evitare di rimanere indietro. llama 2 è alimentato da Meta AI e da altri servizi come Meta Chatbot, Meta Generation Service e Meta Artificial Intelligence Glasses.
In questo vortice di speculazioni, le riflessioni di Mark Zuckerberg sull’open source llama 3 “solo” affascinano e mistificano. In un recente podcast con l’informatico Lex Friedman, Mark Zuckerberg ha dichiarato: “Abbiamo bisogno di un processo per renderlo nuovo e sicuro.
Llama 2 utilizza un’architettura a più livelli che offre versioni con 7, 13 e 70 miliardi di parametri, ciascuna adatta a diversi livelli di complessità e potenza di calcolo. I parametri di LLM agiscono come blocchi neurali che determinano la capacità del modello di comprendere e generare il parlato, e il numero di parametri è spesso correlato alla complessità e alla qualità potenziale dei risultati del modello.
Questo potente modello di intelligenza artificiale è stato addestrato con un ampio corpus di 2.000 miliardi di parole, confermando la sua capacità di navigare in un’ampia gamma di argomenti e contesti e di generare testi simili a quelli umani.
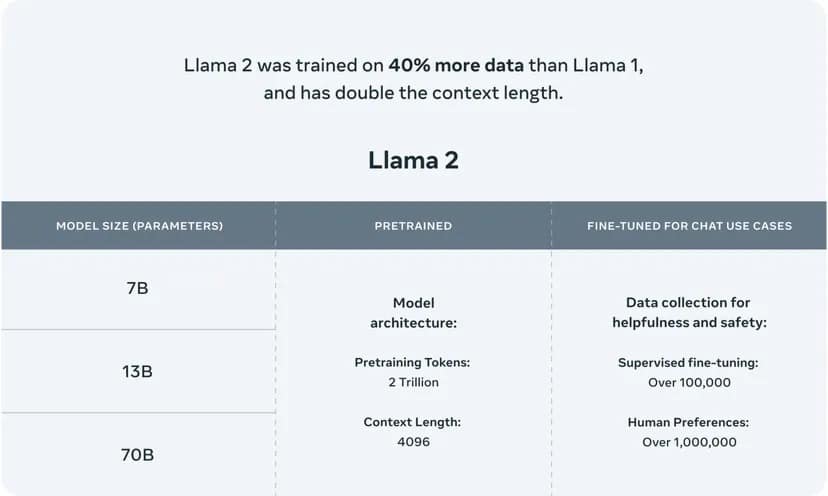
Immagine per gentile concessione di Meta
.