
高度な人工知能を開発する競争において、すべての大規模言語モデルが同じように作られているわけではない。2つの新しい研究が、ChatGPTのような一般的なシステムが、複雑な実世界のタスクでテストされたときの能力に顕著な違いがあることを明らかにした。
パデュー大学の研究者によると、ChatGPTは基本的なコーディングの課題でさえ苦戦しているという。研究チームは、開発者やプログラマーのためのオンラインコミュニティであるStack Overflowの500以上の質問に対するChatGPTの回答を評価した。
“我々の分析によると、ChatGPTが生成した回答の52%は不正解で、77%は冗長である。「しかし、ChatGPTの回答は、その包括性とよく理解された言語スタイルにより、39.34%の確率で好まれています。
対照的に、UCLAとPepperdine University of Malibuの研究では、ChatGPTが難解な医学試験問題に対して優れていることを示しています。ChatGPTは、内科の中でも高度な専門分野である腎臓学の850問以上の多肢選択問題を解いたところ、人間の医学研修医の合格率に近い73%のスコアを獲得しました。
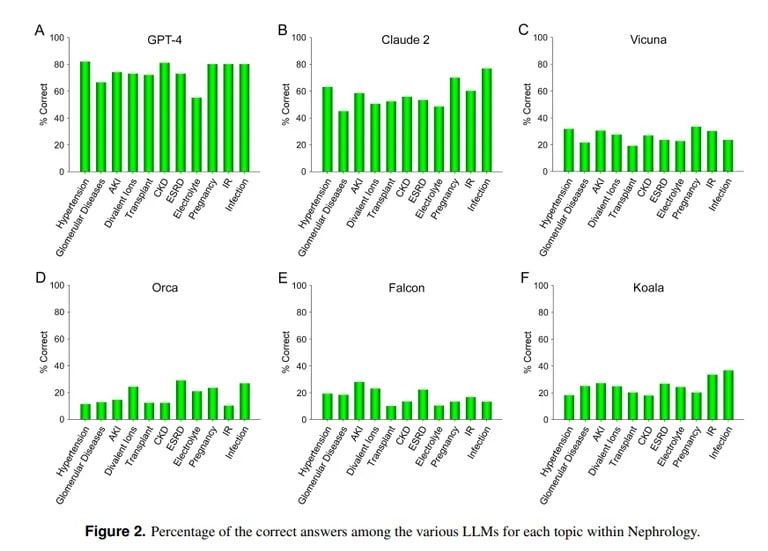
Image credit: UCLA via Arvix
UCLAの研究チームは、「GPT-4が現在、腎臓学の多肢選択式の質問に正確に答える優れた能力を実証していることは、将来の医療アプリケーションにおいて、同様の、そしてより能力の高いAIモデルが有用であることを示している」と結論づけた。
Anthropic社のClaude AIは、正解率54.4%で2番目に優れたLLMであった。チームは他のオープンソースのLLMも評価したが、Vicunaが達成した25.5%が最高で、合格点には程遠かった。
では、なぜChatGPTは医学を得意とし、コーディングを苦手とするのだろうか?MITのコンピューター科学者レックス・フリードマンは、機械学習モデルにはそれぞれ異なる強みがあると指摘する。ChatGPTの医療知識を支えるモデルであるClaudeは、メーカーのAnthropicから独自のトレーニングデータを追加で受け取っている。OpenAIのChatGPTは、一般公開されているデータのみに頼っている。AIモデルは、膨大なデータで適切に訓練されれば、他の多くのモデルよりも優れた結果を出す。
Image courtesy: MIT
しかし、AIは訓練されたパラメーター以外では適切に行動できないため、予備知識がないままコンテンツを作成しようとし、その結果、幻覚と呼ばれる現象が起こる。AIモデルのデータセットに特定のコンテンツが含まれていなければ、その分野で良い結果を得ることはできない。
UCLAの研究者が説明するように、”特定のLLMの計算能力の重要性を否定することなく、現在パブリックドメインにないトレーニングデータ素材に自由にアクセスできないことは、当分の間、さらなる性能向上を達成するための障害のひとつであり続けるだろう。”
ChatGPTのコーディングにおけるポンコツは、他の評価と一致している。TCNが以前報告したように、スタンフォード大学とカリフォルニア大学バークレー校の研究者は、ChatGPTの数学と視覚的推論のスキルが2022年3月から6月の間に急激に低下していることを発見した。当初は素数やパズルに長けていたものの、夏には主要なベンチマークでわずか2%のスコアしか取れなかった。
つまり、ChatGPTはお医者さんごっこはできても、エース・プログラマーになるにはまだまだ学ぶことが多いのだ。しかし、現実はそう遠くない。結局のところ、熟練したハッカーでもある医者を何人知っているだろうか?