
Na corrida para desenvolver inteligência artificial avançada, nem todos os grandes modelos de linguagem são criados da mesma forma. Dois novos estudos revelam diferenças notáveis nas capacidades de sistemas populares como o ChatGPT quando postos à prova em tarefas complexas do mundo real.
De acordo com os investigadores da Universidade de Purdue, o ChatGPT tem dificuldades mesmo com desafios básicos de codificação. A equipa avaliou as respostas do ChatGPT a mais de 500 perguntas no Stack Overflow, uma comunidade online para programadores e programadores, sobre tópicos como depuração e utilização de API.
“Nossa análise mostra que 52% das respostas geradas pelo ChatGPT estão incorretas e 77% são prolixas”, escreveram os pesquisadores. “No entanto, as respostas do ChatGPT ainda são preferidas 39,34% das vezes devido à sua abrangência e estilo de linguagem bem articulado. “
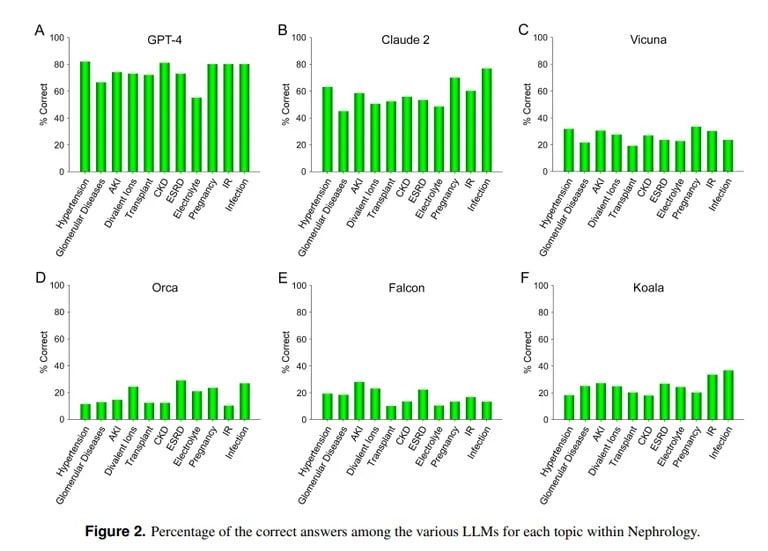
Em contraste, um estudo da UCLA e da Universidade Pepperdine de Malibu demonstra a proeza do ChatGPT em responder a perguntas difíceis de exames médicos. Quando questionado sobre mais de 850 perguntas de escolha múltipla em nefrologia, uma especialidade avançada dentro da medicina interna, ChatGPT obteve 73% – semelhante à taxa de aprovação para residentes médicos humanos.
Crédito da imagem: UCLA via Arvix
“A capacidade superior demonstrada atualmente pelo GPT-4 para responder com precisão a perguntas de escolha múltipla em Nefrologia aponta para a utilidade de modelos de IA semelhantes e mais capazes em futuras aplicações médicas”, concluiu a equipa da UCLA.
O Claude AI da Anthropic foi o segundo melhor LLM com 54,4% de respostas correctas. A equipa avaliou outros LLM de código aberto, mas estes estavam longe de ser aceitáveis, sendo a melhor pontuação de 25,5% obtida pelo Vicuna.
Então, por que é que o ChatGPT é excelente em medicina, mas tem dificuldades em programação? Os modelos de aprendizagem automática têm pontos fortes diferentes, observa Lex Fridman, cientista informático do MIT. O Claude, o modelo por detrás dos conhecimentos médicos do ChatGPT, recebeu dados de formação adicionais do seu criador, o Anthropic. O ChatGPT da OpenAI baseou-se apenas em dados publicamente disponíveis. Os modelos de IA fazem coisas fantásticas se forem devidamente treinados com grandes quantidades de dados, até melhor do que a maioria dos outros modelos.
Imagem cortesia: MIT
No entanto, uma IA não será capaz de atuar corretamente fora dos parâmetros em que foi treinada, pelo que tentará criar conteúdo sem conhecimento prévio do mesmo, o que resulta naquilo a que se chama alucinações. Se o conjunto de dados de um modelo de IA não incluir um conteúdo específico, não será capaz de produzir bons resultados nessa área.
Como explicam os investigadores da UCLA, “sem negar a importância do poder computacional de LLMs específicos, a falta de acesso gratuito a material de dados de formação que não é atualmente do domínio público continuará provavelmente a ser um dos obstáculos à obtenção de um melhor desempenho num futuro previsível”.
O facto de o ChatGPT não conseguir codificar está de acordo com outras avaliações. Como TCN relatado anteriormente, pesquisadores de Stanford e UC Berkeley descobriram que as habilidades de matemática e raciocínio visual do ChatGPT diminuíram drasticamente entre março e junho de 2022. Embora inicialmente adepto de primos e quebra-cabeças, no verão ele marcou apenas 2% nos principais benchmarks.
Portanto, embora o ChatGPT possa brincar aos médicos, ainda tem muito a aprender antes de se tornar um programador de topo. Mas não está longe da realidade, afinal, quantos médicos conheces que também são hackers proficientes?